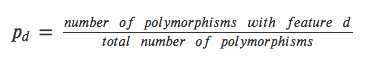Q:
I have read your articles describing FunSeq2 and LARVA. I
find these two frameworks to be the most complete and well-adapted and so, I
am very interested in using them for my analysis. I have installed both
tools and started to run them following the instructions in the
documentation, but I am still encountering a few problems.
First, I have run the web-based version of FunSeq2 on several of my VCF
files and it seems to return the wanted result, with around 10,000+ entries
for each sample. However, when running the tool on the same files in command
line (with the -nc option), I obtain a different result, with no significant
entries returned.
The output returned is:
… Input format check : vcf …
… Format ok …
… Start filtering SNVs with minor allele frequency = 0 …
Warning: sample Sample1 – no SNVs left after filtering against natrual
variations …
I receive a similar result when attempting to run the program on multiple
files at once (both in command line and on the web).
I am also trying to use LARVA on these files; I have managed to install the
tool and I am currently testing it using the example-variants-1.txt file
from the regression suite as the variant file, but the program returns
“Segmentation Fault: 11” with no other error message.
Therefore, I would like to know if you have encountered these errors before
and if so, please let me know about any steps that I can try to correct
them.
A:
I’m glad to hear that you’ve decided to use LARVA for your analyses. I did some investigating with the LARVA codebase to try to figure out what might be causing the segmentation fault. One thing I found was that one of the helper scripts (bigWigAverageOverBed) is provided in its Linux (64-bit) version, so if you run LARVA on a different type of system (e.g. a Mac), the script won’t work. There are versions for other operating systems here (at the end of the page), but for simplicity we only provided the 64-bit Linux version. If that doesn’t fix the issue, could you please tell me everything you can about the environment in which you’re running LARVA (CPU, RAM, operating system, etc.) and the command line parameters you used.
Also, for help on Funseq2, I refer you to my colleague, Shake Lou (cc’ed).
One more thing I just thought of: how are all your input files formatted?
As to the issue about Funseq2, here is some suggestions:
1. The Funseq webserver version is obsolete, and we recommend you to use github version.
2. The latest 2.1.6 version has fixed a bug that might lead to some variant missed from the output.
3. Please use bed format as the output format. I will update vcf format output later.
4. You can also try funseq3.gersteinlab.org, which we have pre-calculated each position’s score for the hg19 genome. If you have a large number of variants to query, we have another good news. We are also testing a rich format whole genome Funseq output file and can let you retrieve the Funseq annotation simply from the command line. If you are interested in this file, we can give you the pre-release testing once it passed our internal QC very soon.