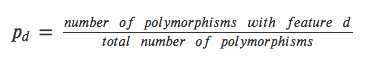Q:
I found your paper regarding to Funseq2 and quite interested at how do you assign weight or calculated weight for each category. From weighted scoring schema, I could see different categories have different weight, but I am not sure how do you decide them .
A lot bit about me: I am interested pediatric genetic diseases and working on a birth cohort at Beijing Children Hospital as assistant professor.
A:
It’s an entropy-based scheme in the paper. It’s also described in
various FunSeq lectures (on lectures.gersteinlab.org).
The details of Funseq2 can be found in our paper: https://genomebiology.biomedcentral.com/articles/10.1186/s13059-014-0480-5. Simply, In Funseq2, we firstly to define a weighted score for each feature based on their distribution of features in random selected common variants. Discrete and continuous features use slightly different way (refer the formula 1 and 2 in the paper).
for a discrete feature, like ‘In sensitive regions’: [see image]
if there are 20 out of 2000000 random common variants are overlapping with sensitive regions, the Pd will be 20/2000000 = 0.0001 , then [see image]
will be used to get the weight for ‘In sensitive regions’
For the continuous feature, it uses:
[see image]